
Pre-processing for NLP
Introduction
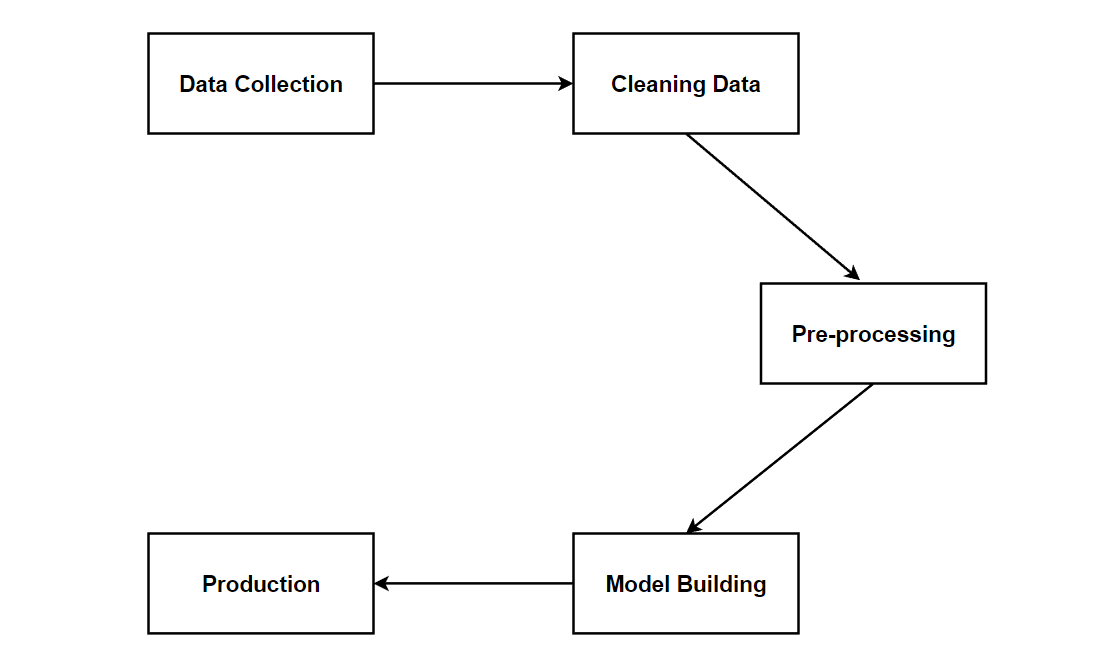
NLP project, just like any other ML project has a simple pipeline which starts with data collection followed by cleaning of data, pre-processing, model building and production.
In this blog post, we will look at the pre-processing step, which holds utmost significance in NLP tasks as it involves transforming raw data into a format that is suitable for modeling, marking the beginning-to-end journey of data preparation.
Pre-processing the natural language might look very simple on first glance but there are many levels to it & research are being done continuously on large scale to find the better way to preprocess.
Let’s see how pre-processing is done for NLP tasks.
To begin our NLP project, we undertake the crucial step of preprocessing the vast amount of unstructured data, which we refer to as the Corpus. Let’s say our data primarily consists of text and requires careful preparation before being used in our NLP tasks. And one of the most basic preprocessing method to start is Tokenization.
Tokenization
Tokenization is the process of breaking down the large text data into smaller pieces known as tokens. Assume that we have a text with 1000 words, we first divide the text into sentences and then sentences to tokens(words in this case).
Well, this sounds simple, but why do we even tokenize the corpus?
Tokenization can be really helpful for tasks such as text segmentation, vocabulary creation, feature extraction, text normalization & language understanding. How tokenization assist the mentioned works might sound unclear right now but as we will be clear by the end of this blog.
In English language, tokens are basically word but punctuations, numbers are also considered as tokens. Let’s try tokenizing english text:
# Import spacy library (!pip install -U spacy if not installed)
import spacy
# Download statistical model for English
!python -m spacy download en_core_web_sm
# Load the downloaded model
nlp = spacy.load('en_core_web_sm')
# Sample text
sample_text = "A quick brown fox forgets to jump."
# Generating tokens with the help of en_core_web_sm model
tokens = nlp(s)
# Iterate over tokens
print([t.text for t in tokens])
Output of the code above will be :

Still, this looks very simple but let's think about it. There are hundereds of language around the world, each with their own rule, punctuation styles, acronyms, abberviated forms etc. Again, we're dividing text to generate tokens on the basis of words & the words are meant to be the single smallest fundamental part of a language that conveys some information/carries some meaning or not. But, how is word defined?
For this let's understand few concepts:
Morphemes are unit of text that can have meaning but wont exist independently. For Example: pre-, post-, a-, un- …etc.
Graphemes are basically even fundamental entity known as letters.
We can have NLP models operating on both words or characters. What to use for our model depends of the problem we have and we can always experiment. Up to now, we are probably clear that tokenization should be done right and it plays important roles in NLP.
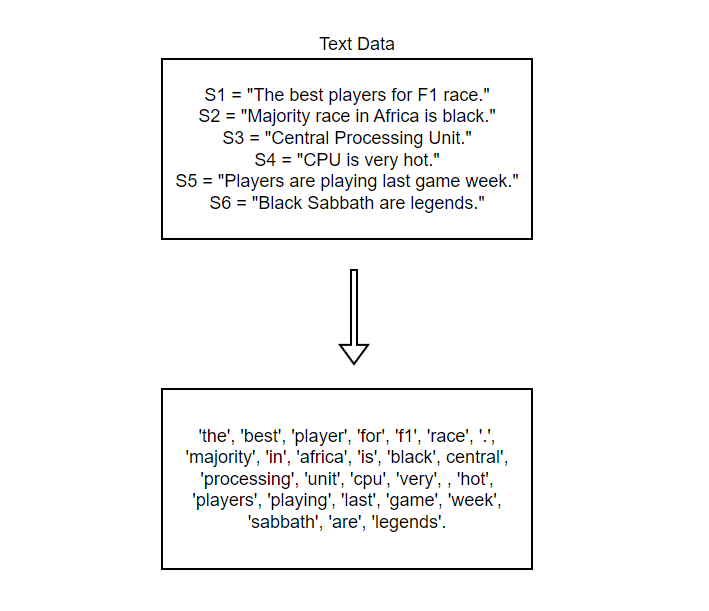
Here, we see that "central", "processing", "unit" & "cpu" are 4 different tokens but they are just same thing used twice.
The next pre-processing step is Case Folding.
Case Folding
Case Folding is just representing the text we have either in all lowercase or uppercase. But what is the reason behind case folding?
Just looking at it doesn’t seem a big things but case folding does have serious advantage. i.e. The number of words in our vocabulary will decrease, same words written in different cases will be recognized as same word & this will help in faster processing.
But it has it’s own problems because the information we are able to retrieve decreases & can hamper the performance and efficiency. It also has problems with acronyms and abbreviated forms.
In order to solve this problem, multiple search engines use rules behind the scenes. For example : Skip the case folding for aronyms.
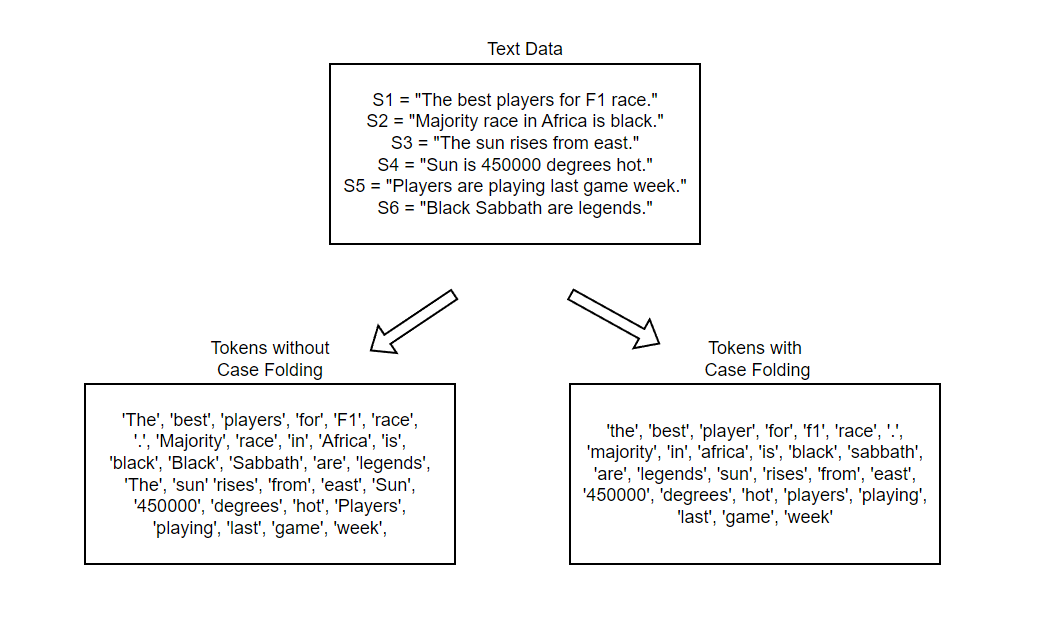
The vocabulary with no case folding have 31 tokens while the one with case folding have 27 and in larger data, the difference can be significant.
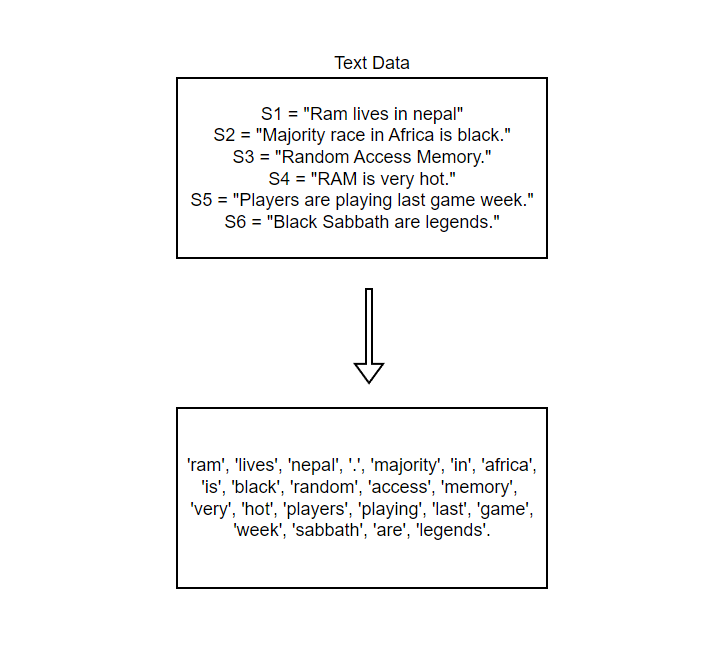
In this example, we can see that "Ram" & "RAM" are given same token and this can result in misleading models.
Stop Words Removal
Stop words are those words that are considered to have little or no significant meaning or impact on the overall understanding of the text. Removing stop words helps reduce the dimensionality of the data and can improve the efficiency of NLP algorithms and models. Examples of stop words in English include: “a”, “an”, “the”, “but”, “I”, “we”, “from” etc. Consider the sentence: “The quick brown fox jumps over the lazy dog.” If we remove the stop words, the sentence would become: “quick brown fox jumps lazy dog.”
# Import spacy library (!pip install -U spacy if not installed)
import spacy
# Download statistical model for English
!python -m spacy download en_core_web_sm
# Load the downloaded model
nlp = spacy.load('en_core_web_sm')
# Print the stop words in this model
print(f" Stop words are : {nlp.Defaults.stop_words}")
# Total stop words
print(f" Total stop words : {len(nlp.Defaults.stop_words)}")
# Sample text
sample_text = "A quick brown fox forgets to jump."
# Generating tokens with the help of en_core_web_sm model
tokens = nlp(s)
# Iterate over tokens
print([t for t in tokens if not t.is_stop])
Output:

But we should not use stop words in every project. Let’s understand it using example:
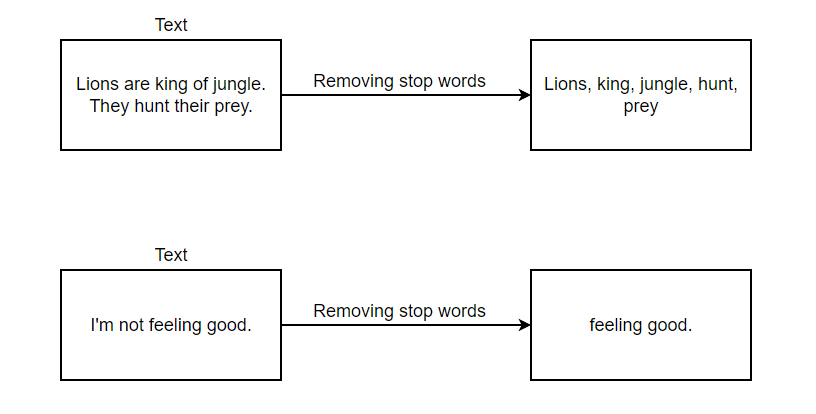
In the example above, we can see that removing stop words worked great for first text but does a terrible job and misinterprets second text. So, removing stop words depends on the problem we’re solving.
Stemming
Stemming is a natural language processing technique used to reduce words to their base or root form, known as the “stem.” The goal of stemming is to simplify word variations and improve text processing efficiency and information retrieval in applications like search engines, text mining, and information retrieval systems.
Stemming helps the words with same stem but different forms to act as same and can help dealing with words that are not in vocabulary.
For Example:
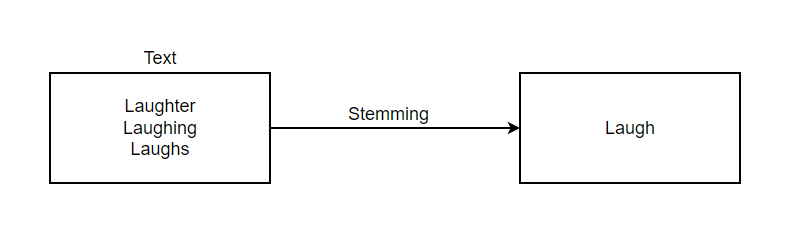
Stemming can also lead to overstemming & understemming which affects the precision and performance of model.
Lemmatization
Lemmatization is a more sophisticated alternative to stemming and it is a technique to reduce words to their lemma/dictionary form. It is more accurate than stemmers because lemmatizers takes into account whether a word is noun, verb, adjective etc. before performing stemming. Because of this, it is preferred over stemmers.
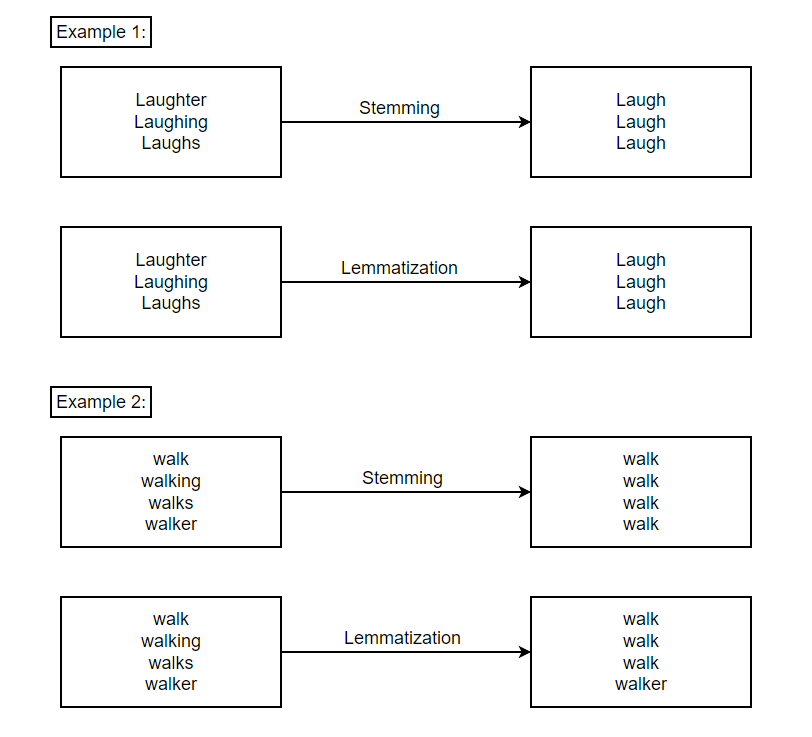
In the figure above, we can see that lemmatizer identified the name walker and kept it as it is while stemmers changed it into walk.
However, it can also degrade performance in cases of ambiguous lemmas, irregular forms, morphologically rich languages and contextual ambiguity.
For Example : Certain words have multiple possible lemmas depending on their context. Lemmatization algorithms may not always select the correct lemma, leading to incorrect transformations. For example, the word “bank” could be a noun or a verb, and lemmatization may not accurately distinguish between “bank” (noun) and “bank” (verb).
The preprocessing techniques we discussed thus far are optional and should be chosen based on the specific problem at hand. So, the idea is to be conservative and avoid these steps unless we obtain clear benefit from them.
The next preprocessing technique we are going to talk about is Part of Speech tagging or commonly called POS tagging.
Part of Speech Tagging
POS tagging is a classification technique used to categorize words in a sentence according to their parts of speech, such as noun, verb, adjective, and more.
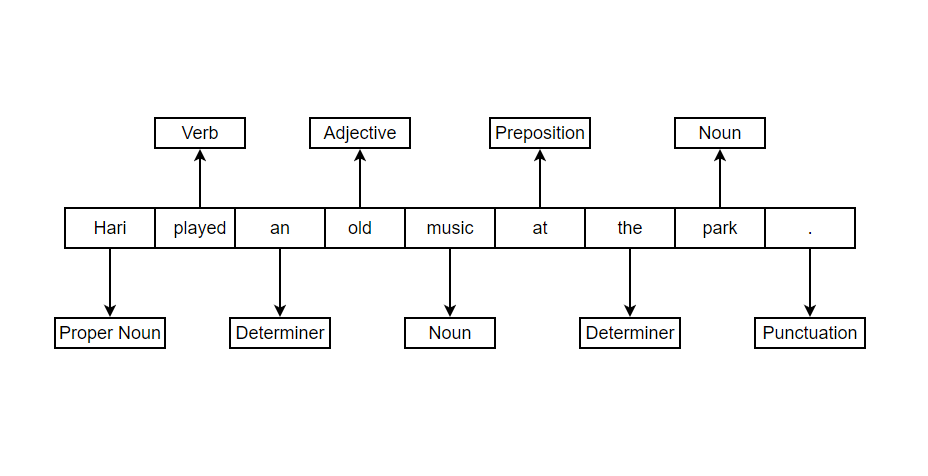
The significance of POS tagging lies in its ability to enhance our comprehension of the text and context. By identifying whether a word functions as a verb, adjective, or noun, we gain valuable insights that aid in understanding the sentence’s intent and meaning. This understanding of the intended context allows us to extract relevant information and grasp the nuances present in the text. Let’s understand the concept by looking at few examples.
Example 1:
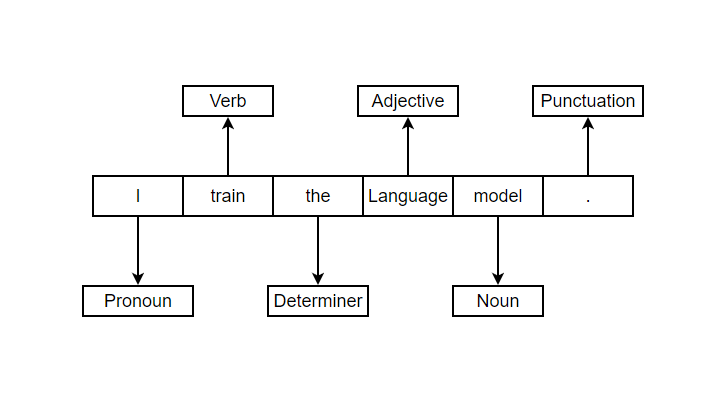
Example 2:
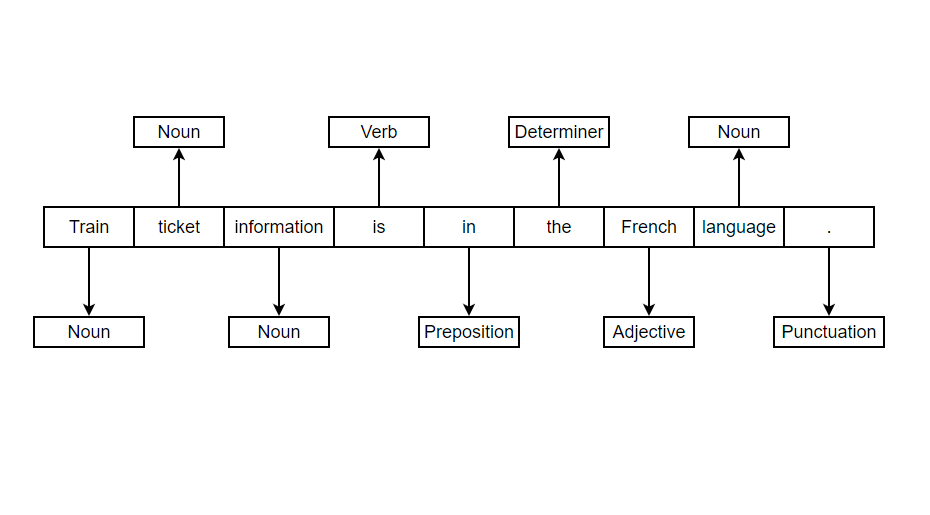
In the examples above, we can see that the word train is acting as a noun in one sentence while as a verb in another. And similarly the word language is acting as an adjective in one and noun in another. This helps in better understanding of context and data.
But POS tagging can have disadvantages such as increased computation overhead and other ambiguity challenges.
Named Entity Recognition (NER)
Named Entity Recognition (NER) is a natural language processing technique that identifies and categorizes specific named entities in text, often marked with the “[PROPN]” POS tag, which denotes proper nouns. NER commonly identified entities such as individuals (labeled as [PER]), locations ([LOC]), and organizations ([ORG]). Furthermore, it extends its scope to include currency, time, dates, and other similar entities, aiding in extracting valuable information, improving information retrieval, and enhancing various language processing applications.
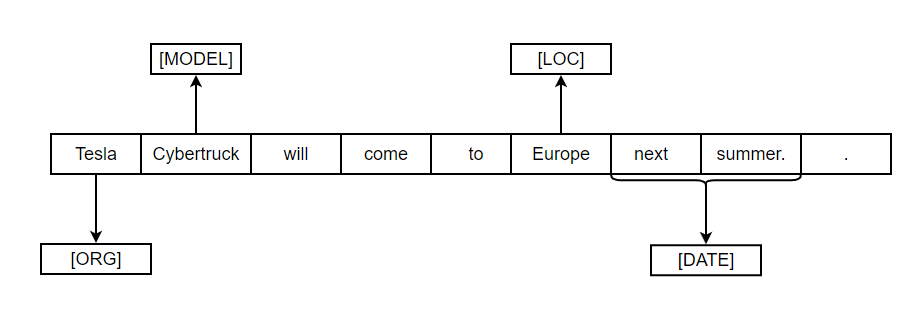
By recognizing and classifying these named entities, NER plays a crucial role in understanding the context and extracting meaningful insights from textual data. NER can also be used to categorize the document in corpus. This can also be extended in other domains and research as well.
However, there are some challenges with NER as an entity can span multiple tokens. So, NER should be able to recognize all the tokens in named-entity. We can see in the example below as Ben White & Declan Rice are name of person but surname of both can be another name & NER should be able to understand that because if White is mentioned, NER needs to recognize whether it is Surname, color or anything else. In the real world, named entities are not always straightforward & can be problematic for NER.
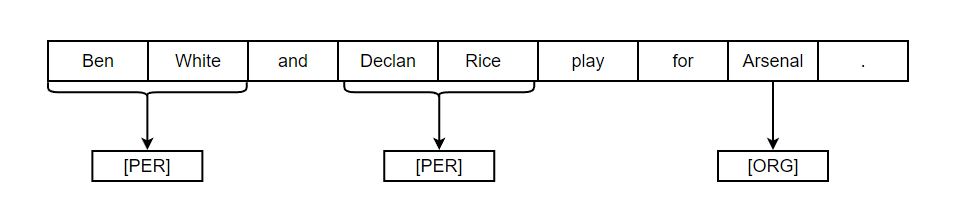
Parsing
Parsing in Natural Language Processing (NLP) involves analyzing and structurally representing a sentence or text based on formal grammar rules. The main goal of parsing is to grasp the sentence’s syntactic structure and construct a parse tree or syntactic structure tree, showcasing the hierarchical connections between words and phrases. This process is pivotal in understanding and interpreting the linguistic patterns within the text, enabling more advanced language processing and comprehension.
In general, there are two common approaches for parsing in NLP.
1. Constituency Parsing
2. Dependency Parsing
Constituency Parsing
Constituency parsing aims to identify and represent the hierarchical constituents or phrases within the sentence according to formal grammar. Basically, it involves breaking down documents to sentences, sentences to phrases & clauses and breaking them further into words.
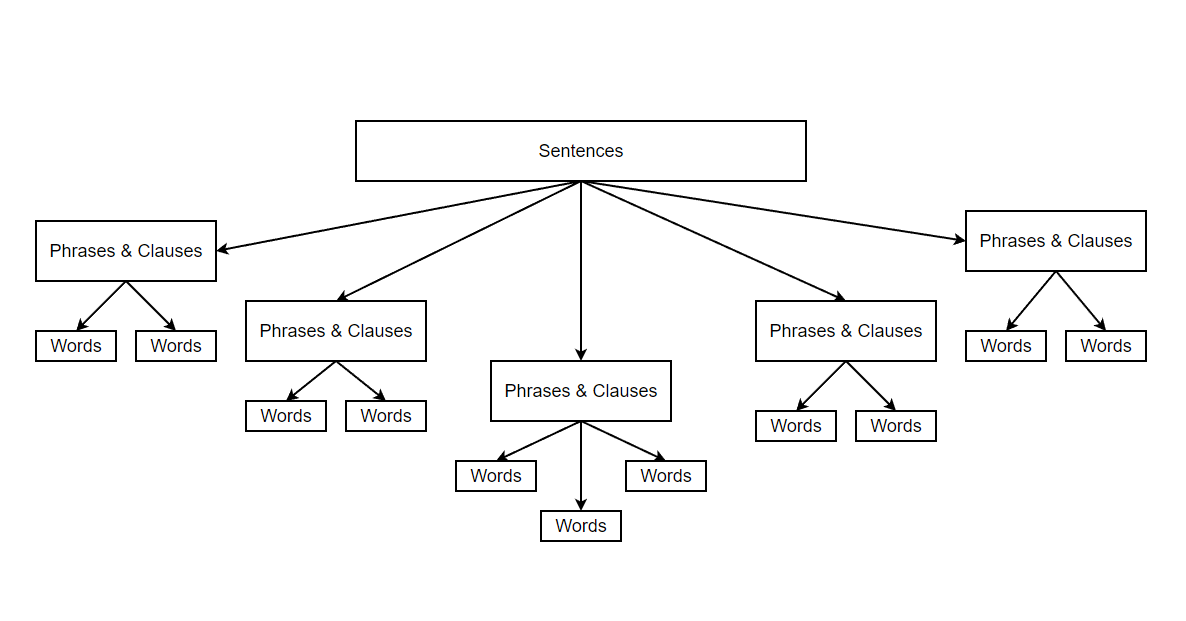
Constituency parsing is achieved with the help of Context Free Grammar (CFG). CFG is just a set of rules on how to build valid sentences from smaller building blocks.
Following are some examples of POS and lexicons.
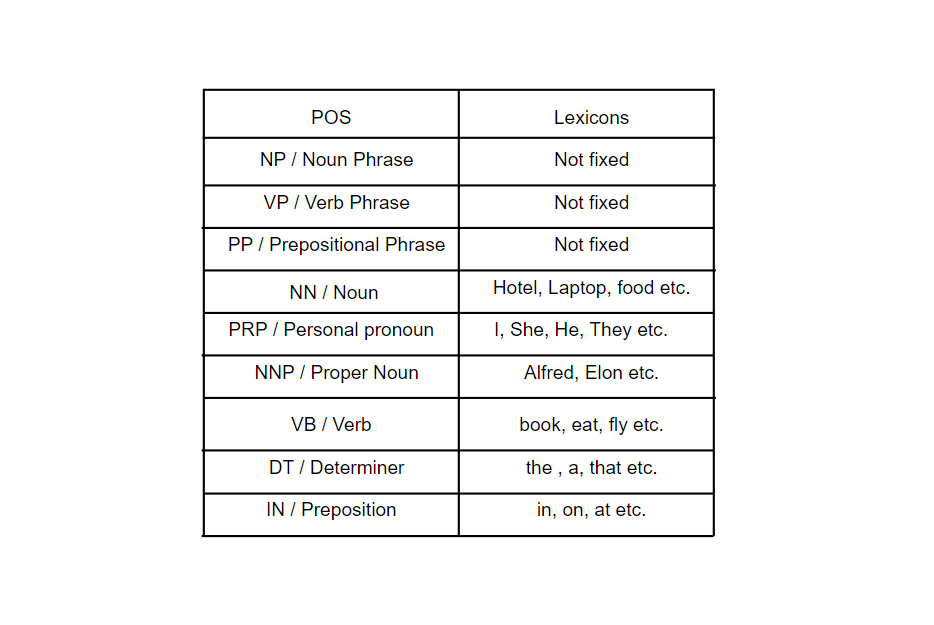
Following some example of rules for CFG:

Let’s look at a simple example:
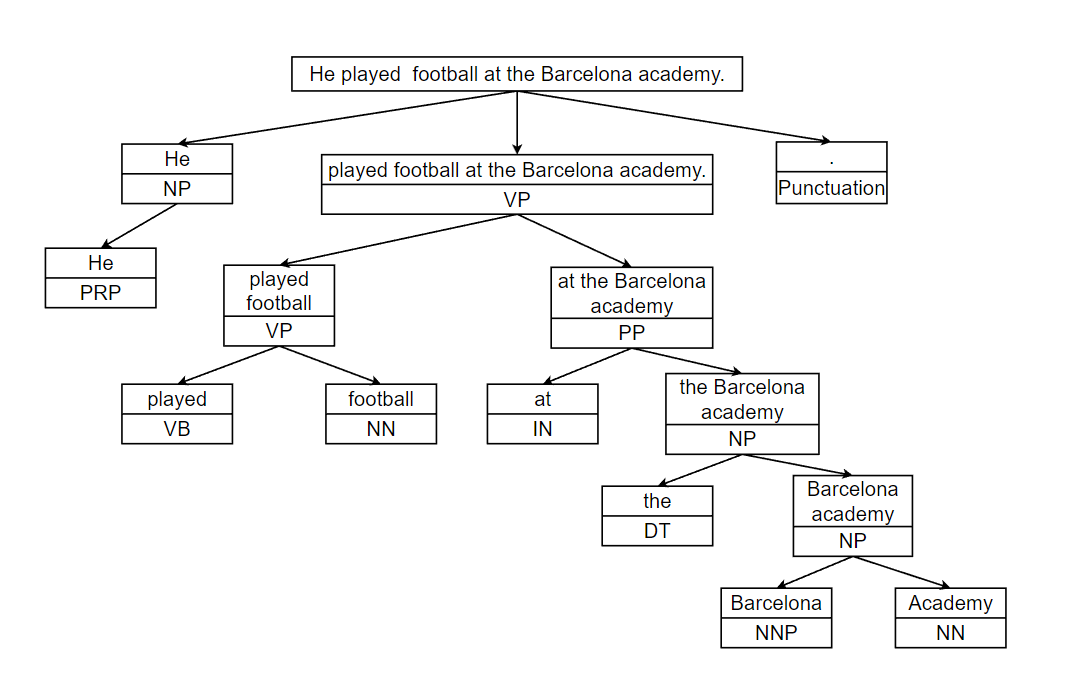
Dependency Parsing
In addition to constituency parsing, another widely used and effective parsing technique in Natural Language Processing (NLP) is dependency parsing. Unlike constituency parsing that focuses on sub-phrases, dependency parsing emphasizes the syntactic relationships between words by employing directed links called dependencies. These dependencies illustrate how words are connected to one another in a sentence, representing the grammatical structure in a more compact and meaningful way.
Dependency parsing is particularly useful for applications that require a deeper understanding of the relationships between words, such as information extraction, sentiment analysis, and question answering. By representing sentences as dependency trees, it becomes easier to identify the subject-verb-object relationships, determine the grammatical roles of different words, and comprehend the overall sentence structure.
Here’s a simple example showing dependency parsing:
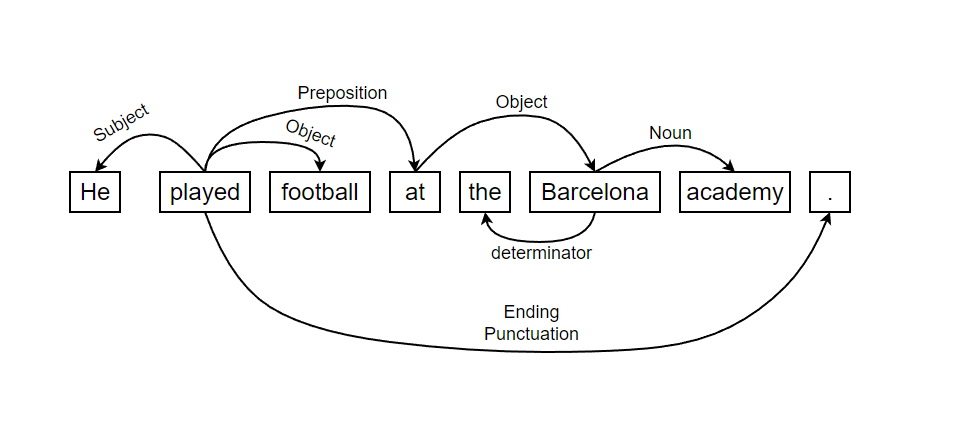
Using dependency parsing or constituency parsingdepends on the problem we are trying to solve. For Example : If our goal need understanding the semantics and syntax of text, then dependency parsing is preferred but if our goal is to extract sub-phrases or specific words, we can use constituency parsing.
The techniques we have discussed so far serve as the foundation for building information extraction systems, information retrieval, and language generation. However, we haven’t yet achieved full machine learning compatibility for our text. Machine learning primarily operates on vectors and involves operations between vectors, iterating multiple times. The text representation we covered in this blog is not suitable for direct application in machine learning algorithms. Hence, we must seek an improved word representation that enables the effective application of algorithms. And, this we will talk about in the next blog.
References for this blog (Click on references for more info):
1. NLP Demystified (Full Course).
2. Text Preprocessing in Natural Language Processing.
3. A Guide to Text Preprocessing Techniques for NLP.
4. Complete Tutorial on Text Preprocessing in NLP.
5. Text Preprocessing in NLP with Python.